Graceful degradation não é luxo, é sobrevivência digital. Imagine o cenário: sua aplicação consulta dados de CPF em tempo real, o usuário clica em “Consultar” e… nada acontece. Tela branca. Spinner infinito. Mensagem genérica de erro. Resultado? O usuário fecha a aba e nunca mais volta.
Segundo o relatório State of API Reliability 2025, o tempo médio semanal de inatividade de APIs saltou de 34 para 55 minutos, um aumento de 60% em apenas um ano. Isso significa que, independentemente da qualidade da API que você consome, falhas vão acontecer. A pergunta real não é “se”, mas “quando” e, principalmente, “como sua interface vai reagir”.
Neste artigo, você vai descobrir estratégias práticas de graceful degradation para construir interfaces que não desmoronam quando a API externa falha. Vamos explorar desde padrões de fallback até técnicas avançadas de cache e circuit breaker, sempre com exemplos aplicáveis ao dia a dia de quem trabalha com APIs de consulta como CPF, CNPJ e CEP. Se você desenvolve aplicações que dependem de serviços externos, este guia foi escrito sob medida para o seu contexto.
O que é graceful degradation?
Antes de mergulhar nas estratégias, vale alinhar o conceito. Graceful degradation é um princípio de design em que o sistema continua funcionando, mesmo com capacidade reduzida, quando um ou mais componentes falham. Em vez de um colapso total, a aplicação “degrada com elegância”, mantendo as funcionalidades essenciais acessíveis.
Isso contrasta diretamente com a abordagem fail-fast, onde o sistema simplesmente para ao encontrar uma falha. Ambas têm seus usos, porém no contexto de interfaces que dependem de APIs externas, a graceful degradation protege a experiência do usuário de maneira muito mais eficiente.
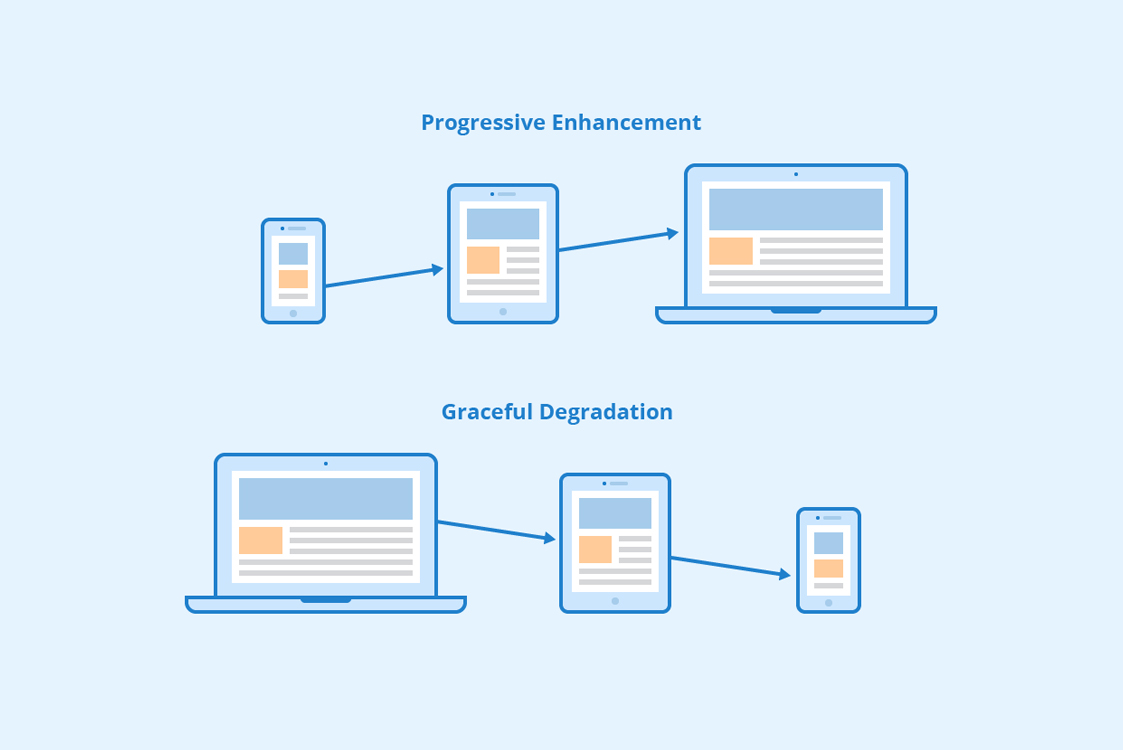
Graceful Degradation vs. Progressive Enhancement
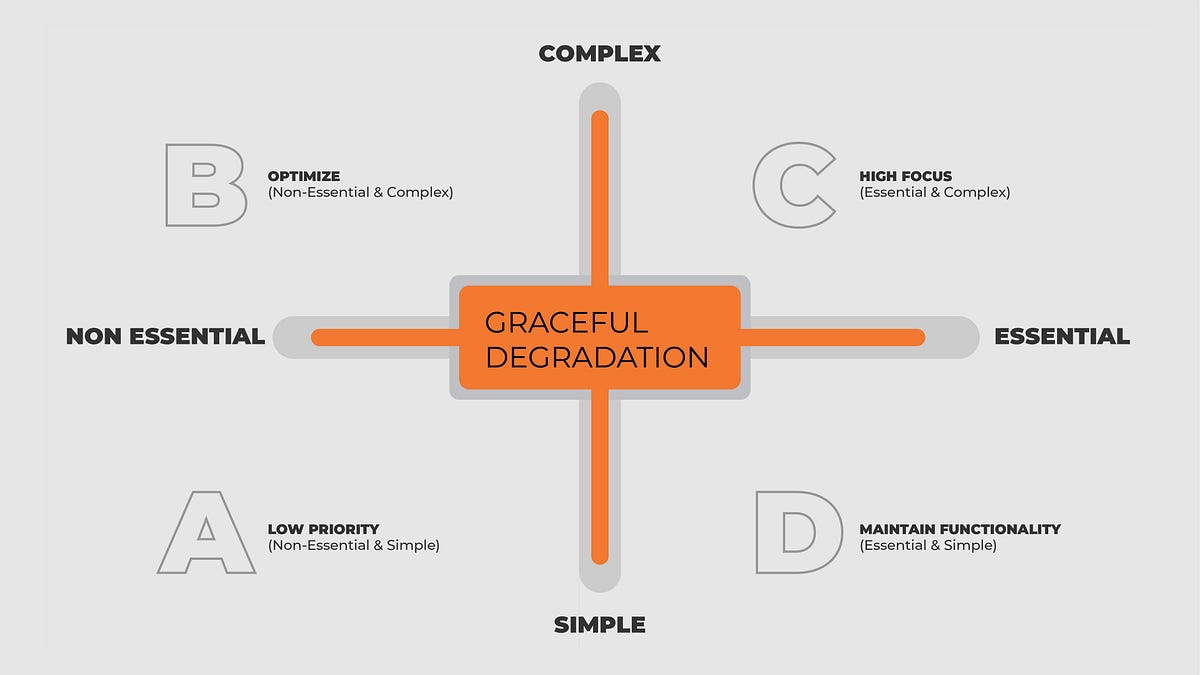
Muitos devs confundem os dois conceitos. Embora complementares, eles partem de direções opostas:
| Aspecto | Graceful Degradation | Progressive Enhancement |
| Ponto de partida | Experiência completa, reduz conforme necessário | Experiência mínima, adiciona conforme suporte |
| Filosofia | “O que acontece quando algo quebra?” | “O que posso adicionar se tudo funcionar?” |
| Foco principal | Resiliência a falhas | Acessibilidade progressiva |
| Quando aplicar | APIs externas, dependências instáveis | Compatibilidade entre navegadores |
| Exemplo prático | Exibir dados em cache quando a API cai | Adicionar animações CSS se o browser suportar |
| Complexidade | Requer planejamento de fallbacks | Requer planejamento de camadas |
No cenário de APIs de consulta, como as disponíveis no Hub do Desenvolvedor para CPF, CNPJ e CEP, a graceful degradation é absolutamente essencial. Afinal, você não controla a infraestrutura do serviço externo. Portanto, precisa estar preparado para quando ele falhar.
Não trate graceful degradation como um “plus” do projeto. Inclua cenários de falha como requisitos funcionais desde o início do desenvolvimento. Cada chamada de API no seu sistema deve ter um plano B documentado antes mesmo de escrever a primeira linha de código.
A boa notícia? Implementar essas estratégias não exige uma refatoração completa. Com os padrões certos, você adiciona resiliência de forma incremental. Inclusive, APIs bem projetadas, como as do Hub do Desenvolvedor, já facilitam esse trabalho ao oferecer respostas padronizadas e tempos de resposta consistentes.
5 Padrões de fallback que salvam sua interface
Agora vamos ao que interessa: as estratégias concretas. Cada padrão abaixo resolve um tipo diferente de falha. O segredo está em combinar vários deles para criar uma camada de resiliência completa.
1. Cache-first com stale fallback
Essa é, sem dúvida, a técnica mais poderosa para APIs de consulta. A ideia é simples: armazene respostas bem-sucedidas localmente e, quando a API falhar, sirva os dados em cache, mesmo que estejam “velhos”.
Para consultas de CEP, por exemplo, os dados raramente mudam. Logo, um cache de 24 horas é perfeitamente aceitável como fallback. Já para consultas de CPF com situação cadastral, o cache pode ter uma janela menor, como 1 hora, já que o dado é mais sensível.
2. Dados estáticos de emergência
Quando nem o cache está disponível, tenha um conjunto de dados estáticos pré-carregados. No caso de consulta de CEP, um banco local com os principais códigos postais pode resolver 80% dos casos.
3. UI skeleton com estado parcial

Em vez de mostrar uma tela em branco, renderize a estrutura da página (skeletons) e preencha apenas os campos disponíveis. Se a API de CNPJ retorna parcialmente, exiba o que conseguiu e sinalize o que está indisponível.
4. Retry inteligente com backoff exponencial
Não desista na primeira tentativa. Implemente retries automáticos com intervalos crescentes. Porém, limite o número de tentativas e mostre progresso ao usuário.
5. Modo offline funcional
Para aplicações mobile ou PWAs, armazene dados essenciais localmente via IndexedDB ou SQLite. Assim, o usuário continua operando mesmo sem conexão.
Como escolher o padrão certo para cada API
Nem toda API merece o mesmo tratamento. Uma consulta de CEP, por exemplo, retorna dados relativamente estáticos. Logo, um cache agressivo de 7 dias funciona perfeitamente como fallback. Já uma consulta de situação cadastral de CPF precisa de dados mais frescos, um cache de 1 a 4 horas seria mais adequado.
A regra de ouro é: quanto mais volátil o dado, menor a janela de cache aceitável. Contudo, mesmo um cache “velho” é melhor que uma tela em branco. Sempre ofereça a melhor informação disponível, sinalizando claramente a “idade” do dado ao usuário.
Um erro muito comum entre desenvolvedores é implementar retry infinito sem backoff. Isso cria um efeito cascata que sobrecarrega a API ainda mais, transformando uma falha temporária em uma indisponibilidade total. Sempre defina um limite máximo de tentativas e intervalos progressivos. Além disso, nunca exiba a mensagem genérica “Erro ao carregar dados” sem contexto, informe ao usuário o que aconteceu e o que ele pode fazer a seguir.
A abordagem em camadas é crucial aqui. Pense da seguinte forma:
- Camada 1 (Retry): Tenta novamente automaticamente
- Camada 2 (Cache fresco): Serve dados recentes do cache
- Camada 3 (Cache expirado): Serve dados antigos com aviso visual
- Camada 4 (Dados estáticos): Mostra informações mínimas pré-carregadas
- Camada 5 (UI de erro): Mensagem clara e orientações para o usuário
Cada camada só entra em ação quando a anterior falha. Dessa forma, o usuário quase nunca vê uma tela de erro puro.
Circuit breaker e Error boundaries: Isolando falhas na interface

Até aqui, falamos sobre o que fazer quando a chamada falha. Agora, vamos discutir como evitar que uma falha contamine toda a aplicação. Dois padrões são fundamentais nessa missão: circuit breaker e error boundaries.
Circuit breaker no frontend
O circuit breaker funciona como um disjuntor elétrico. Quando detecta muitas falhas consecutivas em uma API, ele “abre o circuito” e para de fazer requisições por um período. Em vez disso, ativa automaticamente o fallback.
Esse padrão é especialmente útil quando sua aplicação consulta múltiplas APIs simultaneamente. Se a API de CPF está fora, não faz sentido continuar bombardeando-a com requisições. O circuit breaker detecta a instabilidade, ativa o cache e, periodicamente, tenta uma requisição de “verificação” para saber se a API voltou.
Os três estados do circuit breaker são:
- Fechado: Tudo funciona normalmente, requisições passam direto
- Aberto: API instável, requisições vão direto para o fallback
- Semi-aberto: Permite uma requisição de teste para verificar se a API se recuperou
Error boundaries no react (e equivalentes)
No frontend, error boundaries funcionam como quarentenas. Eles isolam componentes com falha, impedindo que um erro em uma seção derrube a página inteira.
Imagine um dashboard que exibe dados de CPF, CNPJ e CEP em painéis separados. Se a API de CPF falhar, apenas aquele painel mostra a mensagem de indisponibilidade. Os demais continuam funcionando normalmente.
Feature Flags para Degradação Controlada
Feature flags adicionam outra camada de controle. Com elas, você pode desativar features não-essenciais em tempo real quando detectar instabilidade, sem precisar fazer deploy.
Por exemplo: se a API de enriquecimento de dados está lenta, você desativa a consulta extra e mostra apenas os dados básicos. A experiência degrada, porém o core funciona. O usuário nem percebe que algo está diferente.
Equipes que combinam chaos engineering com feature flags validam tanto a resiliência do sistema quanto a prontidão operacional. Ao simular falhas controladas em produção, protegidas por flags que limitam o escopo, você descobre os pontos frágeis antes que os usuários descubram por você.
Na prática, ferramentas como LaunchDarkly, Unleash ou até feature flags simples via variáveis de ambiente permitem esse controle. O importante é que a decisão de degradar seja rápida, reversível e não dependa de um deploy para ser ativada. Quando uma API apresenta instabilidade intermitente, você precisa reagir em segundos, não em minutos.
Como implementar Graceful degradation na prática: Guia passo a passo

Teoria é importante, contudo execução é o que faz a diferença. Vamos montar um roteiro prático para implementar graceful degradation em aplicações que consomem APIs externas.
Passo 1: Mapeie suas dependências
Liste todas as APIs externas que sua aplicação consome. Para cada uma, classifique:
- Criticidade: Essencial, importante ou complementar
- Frequência de falha: Histórico de instabilidades
- Impacto no usuário: O que acontece se falhar
- Alternativa disponível: Cache, dado estático ou nada
Esse mapeamento é o alicerce de toda a estratégia. Sem ele, você vai investir tempo blindando APIs que não precisam e ignorando as que são vitais.
Passo 2: Defina a hierarquia de degradação
Nem todas as funcionalidades têm a mesma importância. Defina claramente quais features podem ser desligadas primeiro e quais devem ser protegidas a todo custo.
Para uma aplicação de consulta de dados, por exemplo:
- Nunca pode falhar: Formulário de busca e exibição de resultados básicos
- Pode degradar: Dados complementares, histórico de consultas
- Pode desativar: Estatísticas, gráficos, features experimentais
Passo 3: Implemente as camadas de fallback
Agora, para cada API mapeada, construa as camadas na ordem que definimos anteriormente: retry → cache fresco → cache expirado → dados estáticos → UI de erro informativa.
A implementação deve ser transparente para o restante da aplicação. Crie um wrapper ou service layer que encapsule toda essa lógica. Assim, o componente de UI simplesmente pede os dados e recebe a melhor resposta disponível, sem precisar saber de qual camada ela veio. Isso mantém o código limpo e facilita testes.
Passo 4: Comunique o estado ao usuário
Esse é, talvez, o passo mais negligenciado. Quando a interface se degrada, o usuário precisa saber. Não tente esconder, informe de forma clara e amigável:
- Use badges ou banners sutis: “Dados atualizados há 15 minutos”
- Diferencie dados em tempo real de dados em cache visualmente
- Ofereça a opção de “tentar novamente” manualmente
- Mostre o status geral do sistema quando aplicável
Segundo dados do relatório Uptrends 2025, equipes que implementam monitoramento multi-step e fallbacks estruturados conseguem resolver mais de 50% dos incidentes de API em menos de 5 minutos. No setor de fintech, esse número chega a 85%. A diferença entre um sistema que colapsa e um que se adapta está justamente nesse preparo antecipado.
Passo 5: Monitore e Itere

Graceful degradation não é “configure e esqueça”. Monitore ativamente:
- Quantas vezes os fallbacks são acionados
- Qual camada de degradação é mais utilizada
- Tempo médio de recuperação das APIs
- Satisfação do usuário durante degradações
Esses dados revelam tanto a eficácia dos seus fallbacks quanto a confiabilidade real das APIs que você consome.
UX de erro: Transformando falhas em confiança do usuário
Aqui está um insight que muitos desenvolvedores ignoram: a forma como sua aplicação falha define a percepção de qualidade mais do que quando ela funciona perfeitamente. Um sistema que degrada com transparência e elegância transmite mais confiança do que um que nunca mostrou um erro, até o dia que quebrou feio.
Os princípios de uma boa UX de erro
A comunicação de falhas precisa equilibrar transparência com otimismo. Veja os princípios que separam uma UX de erro amadora de uma profissional:
- Seja específico, não genérico. “Não foi possível atualizar a situação cadastral neste momento” é infinitamente melhor que “Erro 500”.
- Ofereça próximos passos. Diga ao usuário o que ele pode fazer: tentar novamente, usar dados anteriores ou entrar em contato.
- Mantenha o contexto. Se o usuário preencheu um formulário, não limpe os campos por causa de um erro na API.
- Use tom humano. Telas de erro frias e técnicas assustam. Um tom amigável preserva a relação com o usuário.
- Transforme o erro em feature. O Chrome transformou a tela de “sem internet” em um jogo de dinossauro. Criatividade na falha gera memória positiva.
Componentes de UI essenciais para degradação

Desenvolva estes componentes reutilizáveis no seu design system:
- StatusBanner: Barra superior que informa o estado geral do sistema. Use cores semafóricas: verde para operação normal, amarelo para degradação parcial e vermelho para indisponibilidade crítica.
- StaleDataIndicator: Badge que mostra a “idade” dos dados exibidos. Exemplo: “Dados de 15 min atrás”. Esse componente é crucial para manter a transparência com o usuário.
- RetryButton: Botão com estado de loading e contador de tentativas. Mostre quantas tentativas já foram feitas e ofereça a opção de desistir.
- FallbackCard: Card genérico para substituir componentes que falharam. Deve conter uma explicação breve e ação alternativa.
- OfflineIndicator: Componente que detecta e comunica ausência de conexão. Use a API navigator.onLine combinada com um health check periódico para maior precisão.
Métricas de sucesso da sua estratégia
Como saber se sua implementação de graceful degradation está funcionando? Acompanhe estes indicadores:
- Taxa de abandono durante degradações — deve ser significativamente menor que sem fallbacks
- Tempo médio em estado degradado — quanto menor, melhor a recuperação
- Porcentagem de acionamentos de fallback por API — identifica dependências problemáticas
- NPS ou satisfação durante incidentes — mede a percepção real do usuário
- Tempo de detecção de falha — quanto mais rápido detectar, mais rápido ativar o fallback
No fim das contas, aplicações que implementam graceful degradation de forma madura são percebidas como mais confiáveis. Não porque nunca falham, mas porque falham bem. E isso vale ouro no mercado.
Conclusão
Ao longo deste artigo, exploramos desde os fundamentos da graceful degradation até estratégias avançadas de implementação. Cobrimos padrões de fallback em camadas, circuit breakers, error boundaries, feature flags e, acima de tudo, como comunicar falhas ao usuário de forma que gere confiança em vez de frustração.
O cenário é claro: APIs vão falhar. O downtime global cresceu 60% em um ano. Portanto, a resiliência da sua interface não é diferencial, é requisito. Cada chamada de API no seu sistema deve ter um plano de degradação testado e documentado.
Comece hoje: mapeie suas dependências, defina a hierarquia de degradação e implemente as camadas de fallback que discutimos. E, para simplificar esse trabalho, escolha APIs que já foram projetadas pensando em estabilidade e padronização de respostas.