Rollout é o processo planejado de liberar uma nova versão de software em produção, geralmente de forma gradual, pra controlar riscos e permitir reversão rápida se algo der errado. Pode ser uma feature nova, um upgrade de banco, uma mudança de infraestrutura ou um cliente saindo do monolito pro Kubernetes.
Esse post é pro time de engenharia que quer entender rollout em TI moderno, quais os tipos, quando usar cada um e como executar sem derrubar produção. Sem teoria de gestão: aqui é deploy, observabilidade e rollback.
O que é rollout em TI?
Rollout, em tradução literal, é “desenrolar”. No software, é levar uma nova versão pra produção e disponibilizá-la pros usuários, normalmente de forma escalonada. Você não promove de zero a 100% num clique: libera pra 1%, observa, libera pra 10%, observa, vai aumentando.
Dev e SRE usam três palavras como sinônimos, mas não são:
- Deploy é colocar o código novo no servidor (ou no cluster). O artefato passou a existir naquele ambiente.
- Release é tornar essa nova versão acessível pra alguém. Pode ser um grupo interno, um beta fechado, 5% do tráfego.
- Rollout é a estratégia que governa como a release vai chegar até 100% dos usuários ao longo do tempo.
Dá pra fazer deploy sem release (artefato no cluster com feature flag desligada), release sem rollout gradual (liga pra todo mundo de uma vez, big bang), ou um rollout que dura semanas, com promoção gradual entre regiões.
Quando alguém fala “rollout de sistema” no jargão de TI corporativa, costuma ser implantar um ERP em uma filial nova ou um SAP saindo da matriz pra subsidiária. Aqui a gente trata o termo no sentido usado por dev em 2026: a estratégia de entrega de software em produção.
Por que rollouts gradativos viraram padrão
Há uns 15 anos, deploy era evento. Janela de madrugada, time numa sala, produção derrubada, equipe varando a noite se desse ruim. Big bang em estado puro.
Esse modelo morreu por dois motivos. SaaS e cloud mudaram a expectativa: usuário não aceita mais “manutenção das 2h às 5h”. E microsserviços com containers tornaram viável promover só parte do tráfego pra versão nova.
O conceito-chave é blast radius: o tamanho do estrago caso a versão nova esteja com bug. Num rollout gradual, se o canário com 1% de tráfego vomita erro 500, você impactou 1% dos usuários, não 100%. O MTTR (mean time to recovery) cai porque rollback é rápido, não envolve restore de banco.
Empresas como Netflix e Google fazem milhares de deploys por dia usando feature flags e canary releases. Não é mágica, é arquitetura: cada mudança é pequena, isolável, observável e reversível em segundos.
O Facebook tem o Gatekeeper, sistema interno de feature flags em escala. A Netflix abriu o Spinnaker. O Argo Rollouts orquestra canary e blue-green em cima de Kubernetes. Quando você ouve “estratégia de rollout” hoje, normalmente é uma das seis abordagens abaixo.
Os 6 tipos de rollout (com prós e contras)
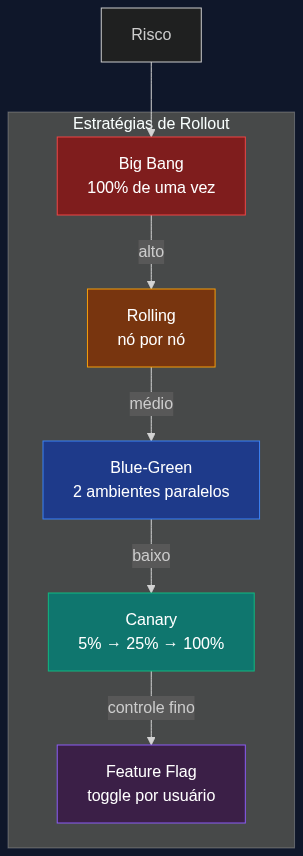
1. Big Bang (rollout total)
Desliga a versão antiga, sobe a nova, todos migram ao mesmo tempo. Rollout dos anos 2000, ainda usado em sistemas legados monolíticos onde não dá pra ter duas versões coexistindo (schema incompatível, dependências externas exclusivas).
- Prós: simples, sem complexidade de roteamento, sem coexistência de versões, libera recursos rápido.
- Contras: blast radius máximo. Se quebrar, quebra pra todo mundo. Rollback exige redeploy completo.
- Quando usar: ambientes internos, sistemas com baixíssimo tráfego, ou quando a mudança é incompatível com a versão anterior (migração de banco com breaking change, por exemplo).
2. Rolling deployment
Você tem N instâncias rodando a versão antiga. Mata uma, sobe uma com a nova, espera ficar saudável, mata a próxima. Repete até trocar todas. É o comportamento padrão do kubectl rollout num Deployment do Kubernetes.
- Prós: sem downtime, sem necessidade de duplicar infraestrutura, nativo no k8s.
- Contras: durante a janela, coexistem versão antiga e nova servindo tráfego (sem controle fino de quem vê o quê). Rollback também é gradual, demora o mesmo tempo que o deploy.
- Quando usar: default razoável pra serviços stateless em Kubernetes, quando você confia no pipeline de CI e não precisa segmentar quem recebe a versão nova.
3. Blue-Green deployment
Dois ambientes idênticos: blue servindo 100% do tráfego, green com a versão nova já deployada e testada, sem tráfego. Quando estiver tudo verde, você muda o load balancer e o tráfego passa 100% pro green num switch. Rollback é trocar de volta.
- Prós: rollback instantâneo (literalmente, troca o ponteiro do LB). Permite smoke test em produção real antes de cortar o tráfego.
- Contras: custo. Você paga por dois ambientes em produção. Migrações de banco viram problema (qual schema vale?).
- Quando usar: serviços críticos onde o custo de duplicar infra compensa o ganho de rollback instantâneo. Comum em fintechs e sistemas com SLA agressivo.
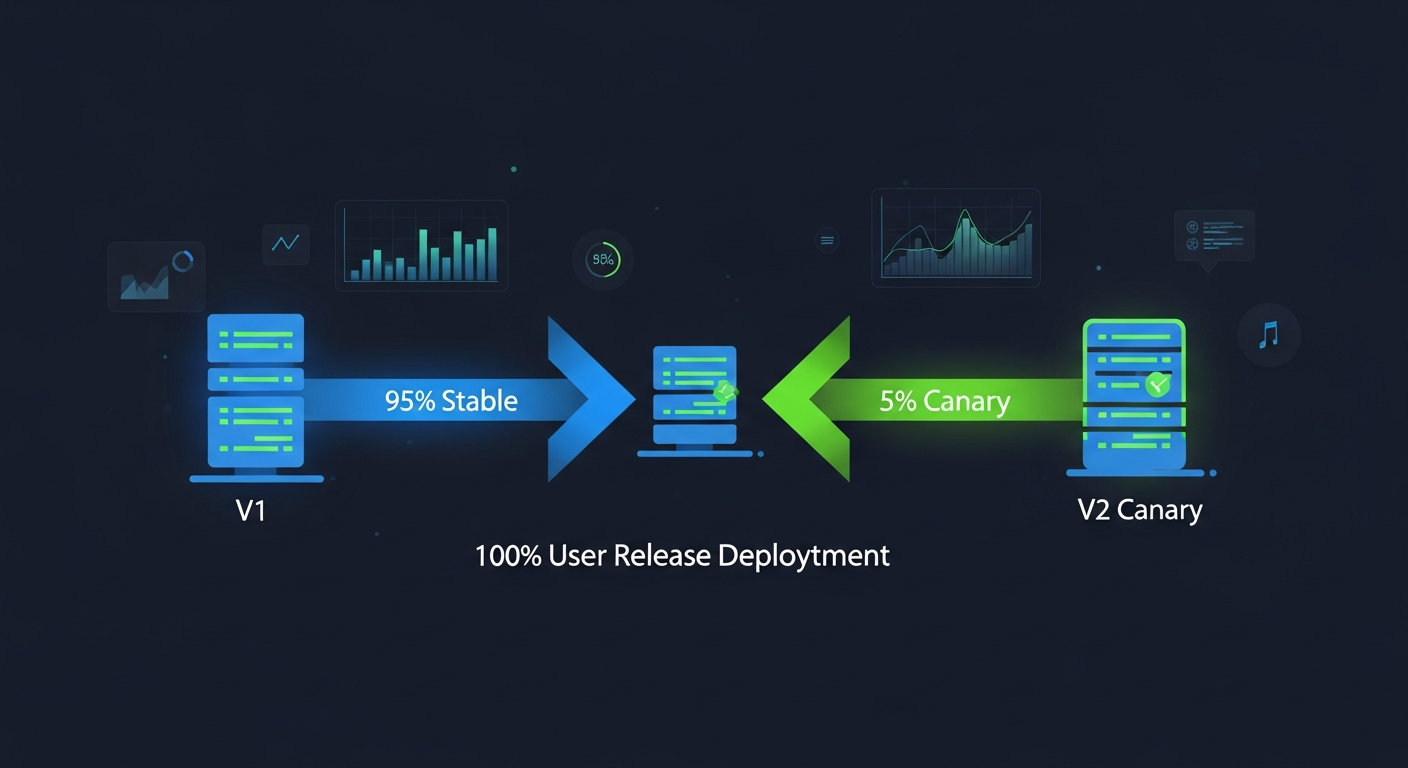
4. Canary release
Nome vem dos canários que mineradores levavam pras minas: se o pássaro morria, era hora de sair. No software, você libera a versão nova pra uma fatia pequena de tráfego (1%, 5%, 10%) e monitora métricas. Se a saúde se mantém, promove. Se piora, rollback antes de impactar a base toda. Martin Fowler descreve a técnica em detalhe.
- Prós: blast radius mínimo. Métricas reais de produção em escala pequena. Permite comparação direta entre versões (canary analysis).
- Contras: exige roteamento ponderado (Istio, NGINX, ALB), observabilidade decente e critérios automatizados de promoção/abort. Não é trivial montar.
- Quando usar: mudanças de risco médio-alto em serviços com tráfego suficiente pra gerar sinal estatístico. Padrão de fato pra times com SRE maduro.
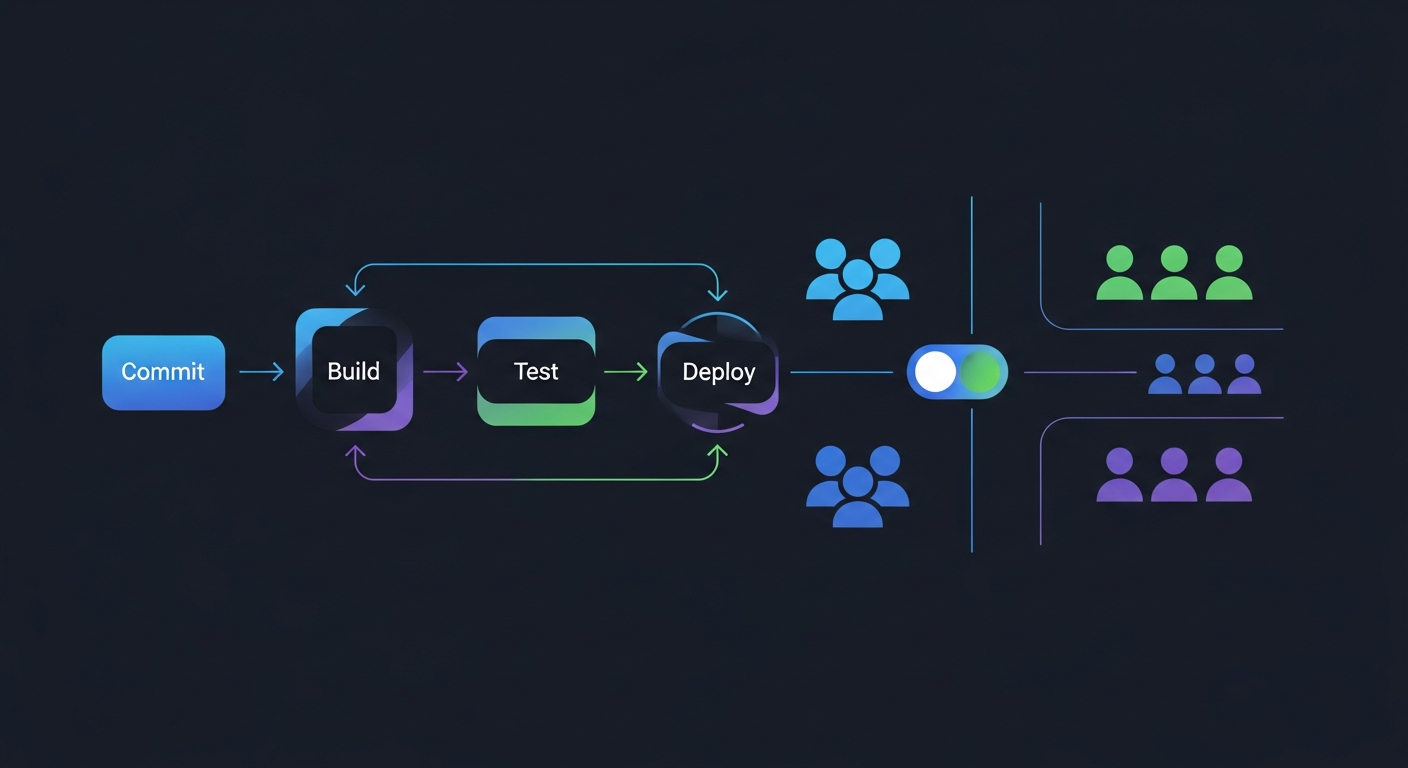
5. Feature flags (dark launch)
Aqui o jogo muda. Deploy do código novo em 100% das instâncias, mas o caminho novo fica atrás de uma flag desligada. Em produção, ninguém vê. Você liga a flag pra 1% dos usuários, depois 10%, depois pro segmento “beta”, depois geral. Deploy e release viram coisas separadas.
A vantagem é desacoplar a entrega do código da exposição da feature. Time de produto controla o release sem precisar de novo deploy. “Rollback” vira desligar a flag, sem CI/CD.
- Prós: rollback instantâneo via toggle. Permite A/B test, segmentação por usuário, kill switch de funcionalidade quebrada sem redeploy.
- Contras: dívida técnica. Flag esquecida no código vira bomba-relógio. Exige disciplina pra remover flags depois que a feature está estável.
- Quando usar: features de produto, experimentos, releases coordenadas com marketing. LaunchDarkly, Unleash, Flagsmith são as ferramentas mais comuns.
6. Shadow / mirror traffic
Você duplica o tráfego real de produção e manda pra versão nova em paralelo, sem que a resposta dela chegue ao usuário. O usuário continua sendo servido pela versão antiga; a nova só recebe a requisição pra você medir performance e correção.
- Prós: testa a nova versão com tráfego real, sem risco pro usuário. Excelente pra validar performance de migração de banco, novo algoritmo de busca, refatoração crítica.
- Contras: caro (você processa cada request duas vezes). Cuidado com side effects: se a versão nova escreve em banco ou chama API externa, vai duplicar operações.
- Quando usar: migrações de plataforma, troca de search engine, validação de novo serviço de pagamento antes de cortar tráfego real. Istio e Envoy oferecem mirroring nativo.
Como planejar um rollout: checklist em 7 passos
- Defina critério de sucesso quantitativo. Não vale “tem que funcionar”. Vale “error rate < 0,5%, p99 < 250ms, conversion rate igual ou maior que baseline”. Sem critério, você promove bug.
- Capture baseline antes do deploy. Dados das últimas 24h da versão atual: latência, erros, throughput, métricas de negócio. É contra esse baseline que o canary vai ser comparado.
- Tenha plano de rollback testado. Comando exato, pessoa responsável, tempo estimado, dependências (banco, cache, fila). Já testou em homologação? Se não, ainda não tem plano.
- Configure monitoramento antes do deploy. Dashboard com as métricas certas aberto antes de tocar no botão. Alerta de SLO burn rate ativo. Não dá pra descobrir o problema pelo Twitter.
- Comunique pra quem precisa saber. Suporte, time de produto e on-call avisados. Se for mudança visível pro usuário, comms externa também (changelog, status page).
- Escolha janela adequada. Não é necessariamente madrugada de domingo. Pra um SaaS B2B do Brasil, pode ser terça-feira 14h, com gente sóbria de plantão. Sexta à noite continua sendo má ideia.
- Faça post-mortem (mesmo quando dá certo). O que rolou conforme esperado? O que poderia ter sido melhor? O que automatizar pra próxima? Rollout maduro é rollout repetível.
Ferramentas que apoiam rollouts modernos
Kubernetes (rolling update): o objeto Deployment do k8s já implementa rolling out por padrão, com maxSurge e maxUnavailable pra controlar a velocidade. A documentação oficial do Kubernetes explica a mecânica em detalhe.
Argo Rollouts: CRD do Kubernetes que estende Deployments com canary, blue-green e análise automática de métricas (Prometheus, Datadog, New Relic). Promove ou aborta o rollout sozinho com base nos critérios que você definir.
LaunchDarkly e Unleash: plataformas de feature flags. LaunchDarkly é o player comercial mais conhecido; Unleash é open-source com versão self-hosted. Ambos resolvem o problema de toggle em produção com SDK pra qualquer linguagem.
Spinnaker: ferramenta de continuous delivery criada na Netflix, multi-cloud, com estratégias de deploy embutidas (red/black, canary, rolling). Curva de aprendizado alta, robusta pra times grandes.
AWS CodeDeploy: serviço gerenciado da AWS que faz rolling, blue-green e canary em EC2, Lambda e ECS. Integra com CloudWatch pra métricas e rollback automático.
Istio: service mesh com traffic splitting nativo via VirtualService. Você define que 95% do tráfego vai pro deployment v1 e 5% pro v2, e o sidecar Envoy executa. Base pra canary release sofisticada em k8s.
Métricas pra avaliar se um rollout está saudável
Promover um canary sem métricas é apostar. Esses são os indicadores que importam:
- Error rate: percentual de respostas 5xx (e 4xx, dependendo do caso). Comparação direta entre canary e baseline. Se subiu, abort.
- Latência p99: tempo de resposta no percentil 99. Médias mentem; p99 mostra o pior caso típico. Degradou 20%, alguma coisa está errada.
- Conversion rate: métrica de negócio. Checkout, signup, click-through. Performance técnica pode estar ok e a versão nova ter quebrado o botão de comprar. Métrica de produto pega isso.
- SLO burn rate: velocidade de consumo do seu error budget. Se dispara durante o rollout, o canary está queimando reserva pro mês inteiro.
- Alertas de SRE: se algum alerta dispara durante o rollout (CPU saturada, fila crescendo, garbage collection alto), trate como sinal de abort até prova em contrário.
Erros comuns em rollouts (e como evitar)
📖 Leitura complementar: Roll out: O que é e como aplicar?
Sem rollback testado. Time confia no kubectl rollout undo e nunca rodou em homologação. No dia D, descobre que o rollback exige migration reversa que não foi escrita. Solução: rollback faz parte do Definition of Done. Sem rollback testado, a feature não está pronta.
Ignorar warm-up de cache. Versão nova sobe, recebe tráfego, cache local está frio. Latência p99 dispara, alerta toca, time aborta achando que tem bug. Era cache. Solução: prewarm das instâncias antes de receber tráfego, ou rollout mais lento.
Mudança de schema sem feature flag. Coluna nova no banco junto com o código que a usa. Se rollback, o código antigo não conhece a coluna. Padrão correto: deploy de schema primeiro (forward compatible), depois deploy do código que usa, com flag. Reverte por flag, não por migration.
Observabilidade depois do deploy. Métrica nova começa a ser instrumentada às 14h, deploy é às 15h. Painel não tem histórico. Solução: instrumentar primeiro, deixar rodar 24-48h pra ter baseline, só então deployar a feature.
Perguntas frequentes sobre rollout
O que é um projeto de rollout?
Projeto de rollout é o conjunto estruturado de atividades pra implantar uma nova versão de software ou sistema em produção. Inclui planejamento, escolha da estratégia (big bang, rolling, canary, blue-green), métricas, plano de rollback e monitoramento pós-deploy. Tem dono, prazo, critério de sucesso e plano B.
O que é rollout em inglês?
“Rollout” já é o termo em inglês. Vem do verbo to roll out, que significa “desenrolar” ou “lançar gradualmente”. Em tecnologia, foi importado direto pro português sem tradução. A tradução literal mais próxima seria “implantação” ou “lançamento gradual”.
O que significa rollout?
Rollout significa o processo de liberar uma nova versão de software ou sistema em produção, normalmente de forma escalonada e controlada. Vem do inglês “to roll out” (desenrolar). Na engenharia de software, é a estratégia que governa como uma release vai chegar até 100% dos usuários.
Como fazer um rollout?
Defina critério de sucesso quantitativo, capture baseline de métricas, escolha a estratégia adequada ao risco (canary, blue-green, feature flag), tenha plano de rollback testado, configure monitoramento antes do deploy, libere gradualmente e faça post-mortem mesmo quando dá certo. Argo Rollouts e LaunchDarkly automatizam boa parte disso.
Qual a diferença entre rollout, deploy e release?
Deploy é colocar o artefato no ambiente (código novo existe no servidor). Release é tornar a versão acessível pra usuários (tráfego começa a chegar). Rollout é a estratégia que governa como a release vai do 0% ao 100% ao longo do tempo. Dá pra deployar sem releasear (feature flag desligada) e releasear sem rollout gradual (big bang).
Próximos passos
Se você está num time que ainda faz big bang em produção, dá pra evoluir sem comprar ferramenta cara. Comece simples:
- Adote rolling deployment como default no Kubernetes (já está lá, só configurar
maxSurgeemaxUnavailabledireito). - Implemente uma feature flag de baixo custo (Unleash self-hosted ou flag em config) na próxima feature não trivial. Sinta a diferença de poder desligar sem redeploy.
- Defina seus 3-5 SLIs principais e crie dashboard único antes do próximo deploy importante. Sem painel, não tem rollout responsável.
- Faça um post-mortem de blameless do último deploy, mesmo que tenha dado certo. O aprendizado mora ali.
Rollout não é cerimônia, é disciplina. Quanto menor a mudança, mais frequente o deploy, mais previsível o resultado. Times que deployam 50 vezes por dia sentem menos medo do que os que fazem 2 vezes por mês, porque cada mudança é pequena e isolável. Comece por aí.
Leituras relacionadas
- CI e CD: O que é?
- Graceful degradation: Estratégias de UI quando a API falha
- Strangler Fig: Como modernizar sistemas monolíticos sem riscos
- Microfrontend: Arquitetura Frontend